Kepadatan Wajah sebagai Proxy Kompleksitas Data: Memahami Batasan Performa AI dalam Lingkungan Penuh
Pelajari bagaimana kepadatan instans (jumlah wajah) secara langsung memengaruhi kinerja AI dalam analisis video, mengungkap batasan mendasar dalam visi komputer dan strategi pengembangan AI.

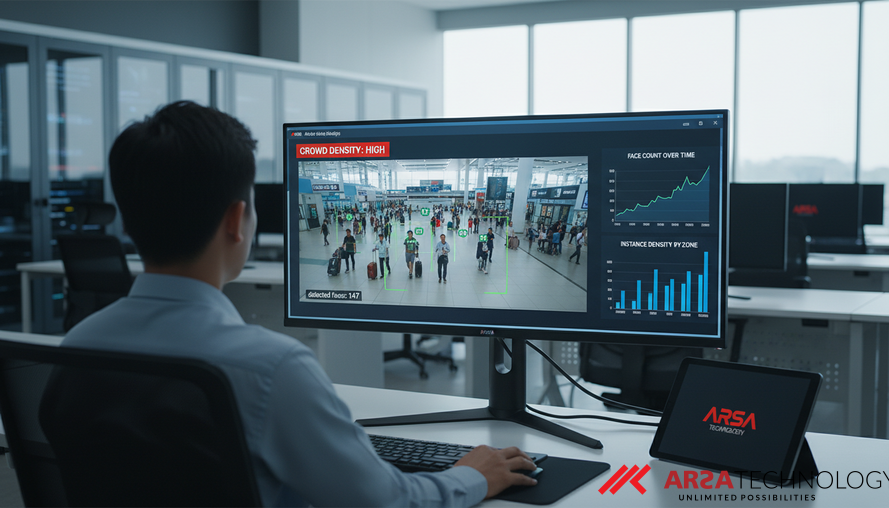
Kepadatan wajah dalam sebuah gambar bukan hanya sekadar detail visual; penelitian terbaru menyoroti bahwa ini adalah faktor krusial yang secara langsung memengaruhi seberapa baik kinerja model Artificial Intelligence (AI) dalam tugas-tugas visi komputer. Sebuah studi akademis berjudul "Face Density as a Proxy for Data Complexity: Quantifying the Hardness of Instance Count" oleh Abolfazl Mohammadi-Seif dan Ricardo Baeza-Yates, yang diterima untuk publikasi di Proceedings of IEEE CAI 2026, menggeser fokus dari inovasi model ke pemahaman mendalam tentang data itu sendiri (Source: https://arxiv.org/abs/2604.09689). Pekerjaan ini menunjukkan bahwa semakin banyak wajah dalam suatu adegan, semakin sulit bagi AI untuk menghitung dan menganalisisnya, bahkan untuk model yang canggih sekalipun.
Secara historis, kemajuan machine learning didorong oleh model yang semakin besar, teknik optimasi yang lebih canggih, dan pre-training yang masif. Namun, terlepas dari kemajuan ini, performa di dunia nyata sering kali mencapai batas tertentu, terutama dalam skenario kompleks seperti adegan yang ramai atau objek yang saling tumpang tindih. Para peneliti ini berpendapat bahwa batas ini bukan karena kurangnya kapasitas model, melainkan karena kompleksitas inheren dari data itu sendiri. Memahami "kekerasan" data ini adalah kunci untuk merancang sistem AI yang lebih efektif dan dapat diandalkan di masa depan.
Mengapa Kepadatan Instans Itu Penting?
Pola pikir dominan dalam machine learning telah lama berpusat pada model: bagaimana membangun arsitektur yang lebih baik, algoritma yang lebih cepat, atau metode pelatihan yang lebih cerdas. Namun, seringkali performa di dunia nyata terhambat oleh masalah yang lebih mendasar, yaitu kompleksitas data. Dalam kasus visi komputer, adegan yang ramai, interaksi multi-objek, atau objek yang saling menutupi (oklusi) dapat menyebabkan model AI kesulitan, bukan karena model tersebut kurang canggih, tetapi karena masalah itu sendiri menjadi lebih sulit secara intrinsik. Fenomena ini tidak hanya terbatas pada visi komputer; hal ini juga muncul dalam long-sequence modeling di NLP (Natural Language Processing) atau prediksi multi-agent dalam robotika.
Studi ini secara spesifik bergeser dari fokus model-sentris ke data-sentris, dengan memformalkan "Kompleksitas Instans" melalui proxy "Kepadatan Instans", yaitu jumlah wajah per gambar. Kepadatan ini dianggap bukan sekadar fitur kontekstual, tetapi dimensi kesulitan yang dapat diukur dan membatasi performa, terlepas dari kapasitas model. Jumlah wajah adalah metrik yang bersih, objektif, dapat dikontrol dengan sempurna, dan secara langsung terkait dengan kesulitan yang muncul di dunia nyata seperti oklusi, variasi skala, keramaian spasial, dan fitur yang saling terkait, tanpa memerlukan anotasi rumit untuk setiap faktor tersebut.
Metodologi dan Temuan Utama
Untuk memastikan keandalan dan generalisasi temuannya, penelitian ini melakukan eksperimen terkontrol pada dua dataset skala besar yang berbeda: WIDER FACE dan Open Images. Kedua dataset ini distratifikasi dan diseimbangkan secara ketat untuk mengandung tepat 1 hingga 18 wajah per gambar. Distribusi jumlah wajah yang identik ini menghilangkan masalah domain shift, perbedaan gaya anotasi, dan kerancuan kepadatan ekstrem, memungkinkan perbandingan langsung antar-dataset dan memperkuat validitas kesimpulan.
Dengan menerapkan protokol eksperimental terkontrol yang sama pada kedua dataset, studi ini berhasil mengisolasi efek kepadatan instans dan menunjukkan bahwa faktor ini sendirilah yang menyebabkan degradasi performa sistematis di berbagai paradigma. Temuan kunci penelitian ini adalah sebagai berikut:
- Penurunan Performa Monotonik: Kinerja model menurun secara monoton seiring dengan peningkatan jumlah wajah, bahkan untuk penambahan satu wajah sekalipun. Tren ini berlaku di berbagai paradigma seperti klasifikasi, regresi, dan deteksi, bahkan ketika model dilatih penuh pada seluruh rentang kepadatan.
Kegagalan Generalisasi: Model yang dilatih khusus pada gambar berdensitas rendah (1 hingga 9 wajah) menunjukkan kegagalan yang jelas ketika dievaluasi pada adegan yang lebih padat. Hal ini mengakibatkan bias penghitungan yang lebih rendah dari sebenarnya (under-counting bias), dengan tingkat kesalahan meningkat hingga 4,6 kali lipat, menunjukkan bahwa kepadatan bertindak sebagai domain shift* atau pergeseran domain yang signifikan. Konsistensi Lintas Paradigma: Efek ini berlaku konsisten di seluruh tugas klasifikasi (membedakan n vs. n+1* wajah), regresi (prediksi jumlah langsung), dan alur penghitungan berbasis deteksi.
Hasil ini, yang direplikasi secara konsisten pada dua benchmark populer dan beragam, menetapkan jumlah wajah sebagai dimensi utama yang sebelumnya kurang dihargai dari kesulitan data. Ini menunjukkan bahwa kepadatan membatasi performa yang dapat dicapai, sebagian besar independen dari arsitektur atau rezim pelatihan AI.
Implikasi Praktis untuk Pengembangan AI
Penelitian ini memiliki implikasi besar bagi para profesional teknologi dan developer AI yang berupaya menerapkan solusi di dunia nyata. Dengan mengidentifikasi kepadatan instans sebagai "penentu kekerasan" data yang dapat diukur, pekerjaan ini mendorong fokus baru pada:
- **Kurasi Dataset yang Sadar Kompleksitas:** Alih-alih hanya mengumpulkan data dalam jumlah besar, penting untuk memastikan bahwa dataset yang digunakan untuk pelatihan secara representatif mencakup berbagai tingkat kepadatan yang akan dihadapi model di lingkungan produksi. Ini berarti tidak hanya memiliki banyak contoh, tetapi juga contoh yang bervariasi dalam kompleksitas.
Penyeimbangan Sampel Berbasis Kepadatan: Praktik standar sering kali menghasilkan dataset dengan bias ke arah adegan berdensitas rendah. Untuk kinerja yang kuat, penting untuk menyeimbangkan dataset* agar mencakup contoh berdensitas tinggi secara memadai. Hal ini membantu model belajar dari contoh-contoh yang lebih sulit, yang seringkali merupakan skenario paling kritis di dunia nyata. Evaluasi Bertingkat Kepadatan: Metrik evaluasi tradisional mungkin tidak secara akurat mencerminkan kelemahan model dalam skenario berdensitas tinggi. Mengembangkan benchmark* yang secara eksplisit menguji model pada berbagai tingkat kepadatan akan memberikan gambaran yang lebih realistis tentang kinerja model. Ini memungkinkan pengembang untuk mengidentifikasi area yang memerlukan perbaikan lebih lanjut dan untuk mengukur kemajuan dalam menangani data yang kompleks.
- Pembelajaran Kurikulum Berbasis Kepadatan: Mengajarkan model secara progresif, dimulai dengan adegan berdensitas rendah dan secara bertahap memperkenalkan adegan yang lebih padat, dapat menjadi strategi pelatihan yang efektif. Pendekatan ini mirip dengan cara manusia belajar, di mana konsep-konsep dasar dikuasai sebelum beralih ke tugas yang lebih kompleks.
Untuk lingkungan yang menuntut presisi tinggi seperti pengawasan keamanan atau manajemen lalu lintas, di mana adegan ramai adalah hal biasa, pemahaman tentang kepadatan instans ini sangat penting. Misalnya, dalam sistem keamanan, kemampuan untuk secara akurat mengidentifikasi individu di keramaian atau memantau area terbatas dengan banyak orang adalah krusial. Solusi seperti analitik video AI dari ARSA, yang dirancang untuk memproses footage CCTV secara real-time dan mendeteksi objek, orang, kendaraan, dan perilaku, harus mempertimbangkan kompleksitas data ini.
ARSA Technology: Menerapkan AI yang Efektif dalam Data Kompleks
Sebagai penyedia solusi AI & IoT yang berpengalaman sejak 2018, ARSA Technology memahami tantangan yang ditimbulkan oleh kompleksitas data di dunia nyata. Produk-produk kami dirancang dengan mempertimbangkan realitas operasional, termasuk kemampuan untuk menghadapi skenario berdensitas tinggi yang sering terjadi di berbagai industri.
Misalnya, ARSA AI Box Series menawarkan sistem AI edge yang telah dikonfigurasi sebelumnya untuk penerapan di lokasi dengan cepat. Dengan memproses aliran video secara lokal di perangkat, ARSA AI Box dapat memberikan wawasan instan dengan latensi rendah dan tanpa ketergantungan cloud, yang sangat penting untuk lingkungan di mana kepadatan instans dapat bervariasi secara dramatis dan data sensitif tidak boleh meninggalkan jaringan. Dalam industri retail, misalnya, AI BOX - Smart Retail Counter dapat menghadapi tantangan kepadatan kerumunan untuk menghitung orang dan menganalisis perilaku pembeli, bahkan di jam-jam sibuk.
Kesimpulan
Penelitian ini secara jelas menunjukkan bahwa kepadatan instans bukan sekadar variabel, tetapi merupakan dimensi fundamental dari kompleksitas data yang membatasi kinerja model AI. Ini adalah pengingat penting bahwa meskipun inovasi model terus berlanjut, pemahaman dan penanganan terhadap karakteristik intrinsik data adalah kunci untuk mencapai performa yang lebih tinggi dan dapat diandalkan dalam aplikasi AI di dunia nyata. Dengan mengakui dan mengkuantifikasi "kekerasan" ini, kita dapat mengembangkan strategi yang lebih cerdas untuk pelatihan model, kurasi dataset, dan desain benchmark, yang pada akhirnya mengarah pada sistem AI yang lebih tangguh dan efisien.
Untuk mendiskusikan bagaimana teknologi AI & IoT dapat membantu Anda mengatasi tantangan kompleksitas data di lingkungan operasional Anda, jangan ragu untuk menghubungi tim ARSA.