Architecting Scalable AI: Introducing the Reasoner-Executor-Synthesizer for O(1) LLM Performance
Explore the Reasoner-Executor-Synthesizer (RES) architecture, a breakthrough AI design for large language models that achieves constant O(1) token cost and eliminates hallucination, ideal for enterprise-scale deployments.

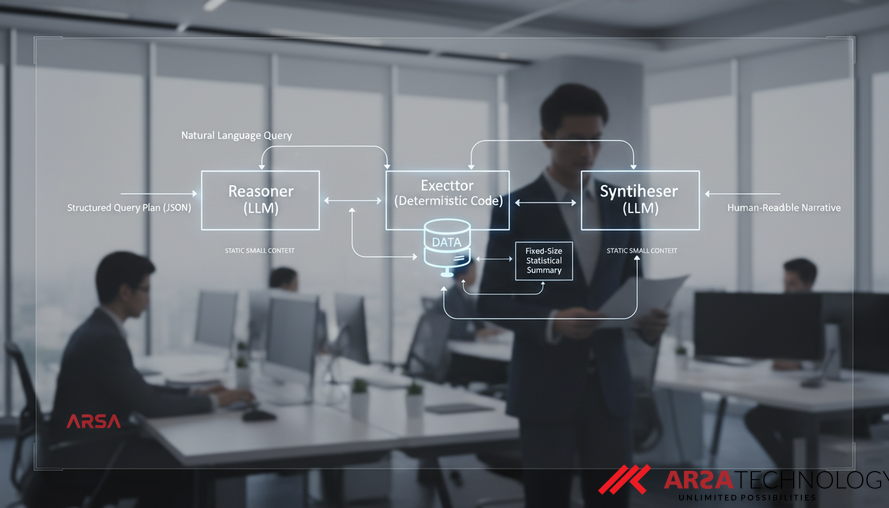
Large Language Models (LLMs) have rapidly become foundational components for autonomous AI agents across various industries, from enhancing customer support to accelerating scientific discovery. While powerful, a common design pattern known as Retrieval-Augmented Generation (RAG) often introduces significant challenges as the volume of data grows. This approach typically involves retrieving relevant documents and feeding them directly into the LLM’s context window alongside the user's query. As highlighted in a recent academic paper by Ivan Dobrovolskyi, this method faces critical limitations, notably the increased risk of "hallucination" and spiraling token costs (Source: Reasoner-Executor-Synthesizer: Scalable Agentic Architecture with Static O(1) Context Window).
The inherent problems with linear scaling in RAG architectures present a significant hurdle for enterprise AI deployments. When an LLM processes longer contexts, its propensity to generate unsupported claims or "hallucinations" grows. This "lost in the middle" problem occurs when critical information is buried among large amounts of irrelevant data, leading to less reliable outputs. Furthermore, the economic implications are substantial: token costs, which directly translate to operational expenses, scale linearly with the number of retrieved documents. For organizations dealing with millions of records, such as in a vast scholarly database, the cost of extracting even simple trends can quickly become prohibitive.
Introducing the Reasoner-Executor-Synthesizer (RES) Architecture
To address these fundamental challenges, the Reasoner-Executor-Synthesizer (RES) architecture proposes a paradigm shift. Instead of overwhelming the LLM with raw data, RES strategically delegates data operations to deterministic code, reserving the LLM for its core strengths: understanding natural language intent and crafting coherent, human-readable narratives. This three-layered design strictly separates responsibilities, leading to two profound benefits: zero data hallucination by design and a revolutionary O(1) token complexity, meaning the LLM's token consumption remains constant regardless of the dataset's size.
The RES architecture is a formally designed system, ensuring each of its three layers operates with distinct responsibilities and clear contracts. This modularity not only enhances reliability but also provides a robust framework for managing complex AI workflows. The structured approach ensures that the system is both scalable and maintainable, crucial factors for enterprise-grade solutions.
Layer 1: The Reasoner – Understanding Intent
The first layer, the Reasoner, is powered by an LLM but with a strictly defined role. Its primary function is to interpret a natural language query (Q) from the user and translate it into a structured query plan (P), typically encoded as JSON. This plan identifies the user's intent—whether it's a request for trend analysis, a comparison, a ranking, or specific statistics—and extracts key parameters such as subjects and temporal constraints.
Crucially, the Reasoner never accesses external data sources, invokes APIs, or generates factual claims about the data itself. Its power lies in its ability to understand human intent, a core strength of LLMs. This strict limitation on its scope ensures that the token cost for the Reasoner remains constant, bounded by the length of the user query and a fixed system prompt, independent of the underlying dataset's size. For example, ARSA Technology leverages advanced AI to interpret complex operational commands, much like a Reasoner, forming the first step in delivering targeted custom AI solutions.
Layer 2: The Executor – Data Retrieval and Aggregation
The Executor is the engine room of the RES architecture, responsible for all data-centric operations. This layer consists entirely of deterministic code, meaning its actions are predictable and repeatable. Upon receiving the structured query plan (P) from the Reasoner, the Executor interacts with the dataset (D) using conventional code and API calls. Its mission is to perform aggregation, filtering, counting, and sorting operations.
The critical innovation here is that the Executor’s output is always a fixed-size statistical summary (S), regardless of how many records (n) were processed in the dataset. For instance, in a system like ScholarSearch, the Executor might query a massive API like Crossref with requests designed to return only counts or faceted data, never individual article records. This process consumes zero LLM tokens. By transforming vast amounts of raw data into a compact, bounded summary, the Executor enables the overall architecture to achieve its O(1) token complexity. This approach mirrors how ARSA’s AI Box Series or AI Video Analytics software processes video streams locally at the edge, aggregating events and metrics without sending raw footage to a central cloud, ensuring data privacy and efficient processing.
Layer 3: The Synthesizer – Generating Insightful Narratives
The final layer, the Synthesizer, receives the fixed-size statistical summary (S) from the Executor. This layer is also powered by an LLM, but its role is limited to translating the statistical findings into a human-readable narrative (N), optionally including configurations for data visualizations. Just like the Reasoner, the Synthesizer never accesses the raw data from the original dataset.
Because the Executor guarantees a constant token length for its output summary, the Synthesizer’s input size is inherently bounded. This ensures that the token consumption of the Synthesizer remains constant (O(1)) with respect to the initial dataset size. This design allows the LLM to focus on what it does best – generating clear, concise, and insightful explanations – without the computational and hallucination risks associated with processing voluminous raw data.
The Breakthrough: O(1) Token Complexity and Hallucination Elimination
The formal complexity analysis of the RES architecture proves its groundbreaking efficiency. Unlike traditional RAG systems, where the context window and thus token cost scale linearly with the dataset size (O(n)), RES achieves total LLM token complexity of O(1). This means the cost associated with LLM processing remains constant, whether the system is analyzing hundreds or hundreds of millions of data points. This is achieved because both LLM layers (Reasoner and Synthesizer) operate on inputs of fixed, bounded size, completely independent of the underlying data volume.
Moreover, the architecture inherently eliminates data hallucination. Since the LLM components of RES never directly interact with raw data records, they cannot generate unverified factual claims based on misinterpretation or "lost in the middle" problems. All factual statements in the final narrative are grounded in the deterministic statistical summaries provided by the Executor, making the system significantly more reliable and trustworthy for mission-critical applications. This design is particularly relevant for sensitive environments where data sovereignty and integrity are paramount, aligning with ARSA Technology’s focus on privacy-by-design and on-premise deployment options for products like the Face Recognition & Liveness SDK.
Real-World Validation: The ScholarSearch Case Study
The practical efficacy of the RES architecture was robustly validated through ScholarSearch, a scholarly research assistant. Backed by the vast Crossref API, which indexes over 130 million articles, ScholarSearch provided a compelling testbed for RES. Across 100 benchmark runs, the system demonstrated a mean token cost of just 1,574 tokens. Remarkably, this cost remained constant, whether the underlying dataset being queried contained 42,000 articles or a staggering 16.3 million articles.
This empirical validation clearly demonstrates that RES delivers on its promise of O(1) token complexity in real-world, large-scale deployments. It proves that enterprises can achieve consistent, predictable operational costs for their AI agents, even when operating on enormous and rapidly growing datasets.
Broader Implications for Enterprise AI
The Reasoner-Executor-Synthesizer architecture represents a significant step forward for enterprise AI, offering solutions to several persistent challenges. Its predictable O(1) token cost model provides financial certainty for IT departments and budget planners, making large-scale AI adoption more economically viable. The elimination of data hallucination by construction drastically improves the trustworthiness and reliability of AI outputs, which is crucial for decision-making in sectors like finance, healthcare, and government.
Furthermore, RES promotes robust data governance and privacy, as raw data never leaves the deterministic processing layer to be interpreted by an LLM. This architectural principle is particularly attractive for regulated industries and organizations with strict data sovereignty requirements. As an AI & IoT solutions provider, ARSA Technology has been experienced since 2018 in delivering systems that prioritize accuracy, scalability, and data control, making architectures like RES highly relevant for deploying our solutions across various industries, from public safety to smart retail.
By separating the generative capabilities of LLMs from the deterministic processing of data, the RES architecture offers a powerful, scalable, and reliable blueprint for the next generation of AI agents. It ensures that the transformative potential of LLMs can be harnessed without succumbing to the limitations of traditional context-window-dependent approaches.
Ready to explore how advanced AI architectures can transform your operations? Discover ARSA Technology’s innovative solutions and contact ARSA for a free consultation to engineer your competitive advantage.
Source: Dobrovolskyi, I. (2024). Reasoner-Executor-Synthesizer: Scalable Agentic Architecture with Static O(1) Context Window. arXiv preprint arXiv:2603.22367. Retrieved from https://arxiv.org/abs/2603.22367