ATTN-FIQA: Meningkatkan Keandalan Sistem Pengenalan Wajah dengan Penilaian Kualitas Berbasis Atensi AI
Pelajari ATTN-FIQA, pendekatan inovatif yang menilai kualitas citra wajah untuk sistem pengenalan wajah yang lebih andal, efisien, dan transparan menggunakan Vision Transformers.

Memahami Tantangan Penilaian Kualitas Citra Wajah (FIQA)
Penilaian Kualitas Citra Wajah (Face Image Quality Assessment – FIQA) adalah komponen fundamental untuk memastikan keandalan sistem pengenalan wajah (Face Recognition – FR). FIQA bertujuan untuk mengukur seberapa baik citra wajah dapat digunakan secara efektif untuk verifikasi identitas otomatis. Dalam konteks sistem biometrik yang semakin canggih, kualitas citra yang masuk sangat krusial untuk mencegah kesalahan, mengurangi upaya penipuan, dan meningkatkan akurasi secara keseluruhan. Tanpa penilaian kualitas yang akurat, sistem FR dapat mengalami kesulitan dalam mengidentifikasi individu dari citra yang buram, terhalang, atau memiliki pencahayaan buruk, yang pada akhirnya memengaruhi efisiensi operasional dan keamanan.
Metode FIQA yang ada saat ini, meskipun mampu mencapai kinerja yang kuat, seringkali memerlukan prosedur komputasi yang mahal. Ini termasuk berbagai pendekatan seperti beberapa forward pass (proses data melalui jaringan saraf), backpropagation (penyesuaian bobot model), atau pelatihan tambahan yang memakan waktu dan sumber daya. Selain itu, sebagian besar pendekatan ini menghasilkan skor kualitas skalar yang opaque, artinya skor tersebut tidak memberikan penjelasan spasial tentang mengapa suatu citra dianggap berkualitas rendah. Ketiadaan interpretasi spasial ini membatasi kemampuan praktisi untuk memahami bagian mana dari wajah yang paling berkontribusi pada penurunan kualitas, menyulitkan proses debugging atau peningkatan sistem dalam aplikasi biometrik praktis.
Peran Vision Transformers dalam Analisis Kualitas Citra Wajah
Seiring dengan kemajuan pesat dalam kecerdasan buatan, arsitektur Vision Transformer (ViT) telah menunjukkan kinerja yang luar biasa dalam tugas pengenalan wajah. ViT bekerja dengan memecah citra menjadi potongan-potongan kecil (patch) dan kemudian menggunakan mekanisme "atensi" untuk memahami hubungan antara setiap patch tersebut. Berbeda dengan jaringan saraf konvolusional tradisional, ViT memiliki kemampuan inheren untuk mempelajari "saliency" atau daerah penting dalam citra secara alami, tanpa perlu pelatihan khusus untuk tujuan tersebut. Ini berarti pola atensi yang dihasilkan ViT secara intrinsik mengodekan kepentingan spasial, menunjukkan bagian-bagian citra mana yang paling menarik perhatian model.
Meskipun potensi ViT ini telah terungkap dalam berbagai aplikasi, metode FIQA berbasis ViT yang ada sebelumnya masih mengharuskan pelatihan tambahan atau modifikasi arsitektur yang kompleks. Hal ini memunculkan pertanyaan mendasar: bisakah skor atensi pre-softmax dari model FR berbasis ViT yang sudah dilatih sebelumnya langsung berfungsi sebagai indikator kualitas citra wajah tanpa pelatihan tambahan? Pemahaman tentang bagaimana model mengarahkan "perhatian" mereka pada fitur-fitur wajah yang diskriminatif ini menjadi kunci untuk mengembangkan solusi FIQA yang lebih efisien dan transparan.
ATTN-FIQA: Pendekatan Inovatif Berbasis Atensi
ATTN-FIQA hadir sebagai pendekatan inovatif yang menjawab pertanyaan tersebut dengan memanfaatkan sifat intrinsik Vision Transformers. Kami berhipotesis bahwa magnitudo atensi pre-softmax secara intrinsik mengodekan kualitas citra wajah sebagai hasil sampingan dari tugas pengenalan itu sendiri. Skor atensi pre-softmax adalah nilai-nilai mentah sebelum melewati fungsi softmax yang mengubahnya menjadi distribusi probabilitas. Pentingnya pre-softmax adalah karena nilai ini mempertahankan perbedaan magnitudo yang jelas, yang sangat cocok untuk penilaian kualitas.
Bagaimana cara kerjanya? Untuk citra berkualitas tinggi dengan fitur wajah yang diskriminatif (misalnya, mata, hidung, mulut yang jelas), model akan mampu melakukan penyelarasan query-key yang kuat, menghasilkan pola atensi yang terfokus dan memiliki magnitudo tinggi pada area-area wajah yang relevan dengan identitas. Sebaliknya, citra dengan degradasi kualitas seperti keburaman, oklusi, atau pencahayaan yang buruk akan memperkenalkan ambiguitas pada patch citra, melemahkan penyelarasan query-key, dan menghasilkan pola atensi yang menyebar (diffuse) dengan magnitudo yang lebih rendah. Ini mencerminkan ketidakpastian model dalam mengidentifikasi fitur-fitur penting.
ATTN-FIQA mengekstraksi matriks atensi pre-softmax dari blok transformer terakhir model FR berbasis ViT yang sudah dilatih sebelumnya. Kemudian, informasi atensi dari berbagai kepala atensi (multi-head attention) dan patch digabungkan. Skor kualitas tingkat citra dihitung melalui rata-rata sederhana. Pendekatan ini hanya memerlukan satu kali forward pass melalui model yang sudah dilatih, tanpa modifikasi arsitektur, backpropagation, atau pelatihan tambahan. Dengan demikian, ATTN-FIQA menawarkan solusi yang sangat efisien dalam hal komputasi. Ini adalah terobosan yang dapat dimanfaatkan dalam berbagai sistem, seperti solusi AI Video Analytics yang dikembangkan oleh ARSA Technology, di mana efisiensi dan keakuratan adalah kunci.
Interpretasi Spasial dan Validasi Empiris
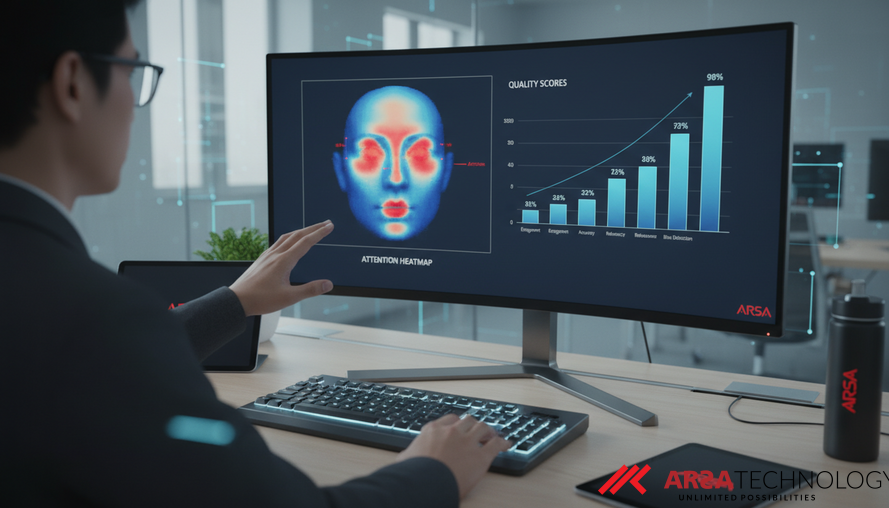
Salah satu kontribusi utama ATTN-FIQA adalah kemampuannya untuk menyediakan interpretasi kualitas spasial. Ini berarti model tidak hanya memberikan skor kualitas, tetapi juga mengungkapkan wilayah wajah mana yang paling berkontribusi terhadap penentuan kualitas. Melalui visualisasi atensi (seperti peta panas), praktisi dapat melihat secara langsung area mana yang diperhatikan oleh model, dan bagaimana perhatian tersebut berubah seiring dengan perubahan kondisi citra. Misalnya, pada citra berkualitas tinggi dengan pose frontal, atensi akan terfokus pada fitur wajah diskriminatif. Namun, pada citra yang terdegradasi akibat oklusi, pose ekstrem, atau penutup wajah, atensi cenderung menyebar dan memiliki magnitudo rendah, mencerminkan ketidakpastian model (seperti yang ditunjukkan dalam Gambar 2 dari studi aslinya).
Studi ini melakukan evaluasi komprehensif pada delapan dataset benchmark dan empat model FR yang berbeda, menunjukkan bahwa skor kualitas berbasis atensi ini secara efektif berkorelasi dengan kualitas citra wajah dan memberikan interpretasi spasial yang berarti. Validasi empiris pada dataset SynFIQA (Gambar 1 dari studi aslinya) secara jelas menunjukkan bahwa citra dengan kualitas rendah (Q0) memiliki skor rata-rata terendah, yang kemudian meningkat secara monoton hingga citra referensi (Ref) mencapai skor tertinggi. Korelasi sistematis ini memvalidasi hipotesis bahwa magnitudo atensi pre-softmax secara intrinsik mengodekan kualitas citra wajah. Kemampuan ini sangat berharga dalam aplikasi seperti AI Box - Basic Safety Guard untuk memastikan citra yang masuk memenuhi standar analisis keamanan, atau di sektor ritel dengan AI Box - Smart Retail Counter untuk analisis perilaku pelanggan yang akurat, di mana kualitas citra memengaruhi keandalan data yang dikumpulkan di berbagai industri.
Penerapan Praktis dan Keunggulan Kompetitif
Keunggulan ATTN-FIQA dalam hal efisiensi dan interpretasi memiliki implikasi praktis yang signifikan. Dalam sistem pengenalan wajah di dunia nyata, data citra seringkali tidak sempurna. Adanya metode FIQA yang cepat dan transparan memungkinkan:
- Peningkatan Keandalan Sistem Biometrik: Dengan menyaring citra berkualitas rendah secara otomatis, sistem FR dapat bekerja lebih akurat dan mengurangi tingkat kesalahan.
Optimasi Pengambilan Data: Sistem dapat memberikan umpan balik kepada pengguna untuk menangkap citra yang lebih baik, misalnya saat proses e-KYC* (Know Your Customer) atau akses fisik.
- Deteksi Sumber Degradasi Kualitas: Kemampuan interpretasi spasial membantu mengidentifikasi akar masalah degradasi kualitas (misalnya, pencahayaan buruk, kacamata, atau penutup kepala), memungkinkan perbaikan yang lebih tepat.
- Kepatuhan dan Pencegahan Penipuan: Memastikan kualitas citra yang tinggi sangat penting untuk mematuhi regulasi keamanan dan mencegah upaya penipuan identitas.
ARSA Technology, dengan pengalaman sejak 2018 dalam membangun masa depan dengan AI dan IoT, secara konsisten menghadirkan solusi yang dirancang untuk mengurangi biaya, meningkatkan keamanan, dan menciptakan aliran pendapatan baru. Pendekatan seperti ATTN-FIQA yang menawarkan efisiensi komputasi tinggi dan interpretasi spasial sejalan dengan visi ARSA untuk menghadirkan AI yang praktis, terbukti, dan menguntungkan. Kemampuan untuk menganalisis dan memahami kualitas citra wajah tanpa pelatihan tambahan dan dengan satu forward pass akan mempercepat implementasi solusi AI yang tangguh dan cerdas di berbagai sektor.
Kesimpulan
ATTN-FIQA mewakili langkah maju yang signifikan dalam bidang Penilaian Kualitas Citra Wajah. Dengan memanfaatkan kemampuan inheren Vision Transformer untuk mempelajari atensi spasial, metode ini menyediakan cara yang efisien, transparan, dan dapat diinterpretasikan untuk menilai kualitas citra wajah. Keunggulannya dalam efisiensi komputasi (hanya memerlukan satu forward pass pada model yang sudah dilatih) dan interpretasi spasial (menunjukkan wilayah wajah yang paling penting) menjadikannya alat yang sangat berharga untuk sistem pengenalan wajah generasi berikutnya. Dengan solusi seperti ini, organisasi dapat membangun sistem biometrik yang lebih tangguh, aman, dan dapat diandalkan, memaksimalkan nilai dari teknologi AI.
Sumber: ATTN-FIQA: Interpretable Attention-based Face Image Quality Assessment with Vision Transformers
Untuk menjelajahi lebih lanjut bagaimana solusi AI dan IoT dari ARSA Technology dapat mengoptimalkan operasional bisnis Anda, kami mengundang Anda untuk menghubungi tim ARSA dan mendapatkan konsultasi gratis.