Blind-Spot Mass: Mengukur Risiko Cakupan Implementasi Sistem AI dengan Kerangka Good-Turing
Pahami Blind-Spot Mass, kerangka kerja Good-Turing untuk mengukur risiko cakupan sistem AI. Artikel ini menjelaskan cara mengidentifikasi daerah operasi yang kurang didukung data, penting untuk keandalan AI di dunia nyata.

Pendahuluan: Mengapa Akurasi Saja Tidak Cukup dalam AI Real-World
Dalam pengembangan sistem Machine Learning (ML) modern, fokus seringkali tertuju pada mencapai akurasi tinggi pada set data uji. Namun, akurasi yang baik di laboratorium tidak selalu menjamin keandalan saat sistem tersebut diterapkan di dunia nyata. Ada tantangan fundamental yang sering terabaikan: sejauh mana data pelatihan benar-benar mencerminkan seluruh spektrum kondisi yang akan dihadapi model dalam operasi sehari-hari.
Distribusi kondisi operasional di dunia nyata seringkali bersifat "heavy-tailed", artinya sebagian besar probabilitas terkonsentrasi pada kondisi yang umum, sementara ada "ekor panjang" dari kondisi-kondisi yang valid namun jarang terjadi. Kondisi-kondisi langka ini secara struktural kurang terwakili dalam kumpulan data pelatihan dan evaluasi yang terbatas. Akibatnya, sebuah model bisa terlihat sangat akurat pada set data uji standar, tetapi menjadi tidak dapat diandalkan di sebagian besar area ruang kondisi implementasi, bukan karena pergeseran distribusi, melainkan karena area tersebut secara intrinsik tidak terlihat selama pelatihan.
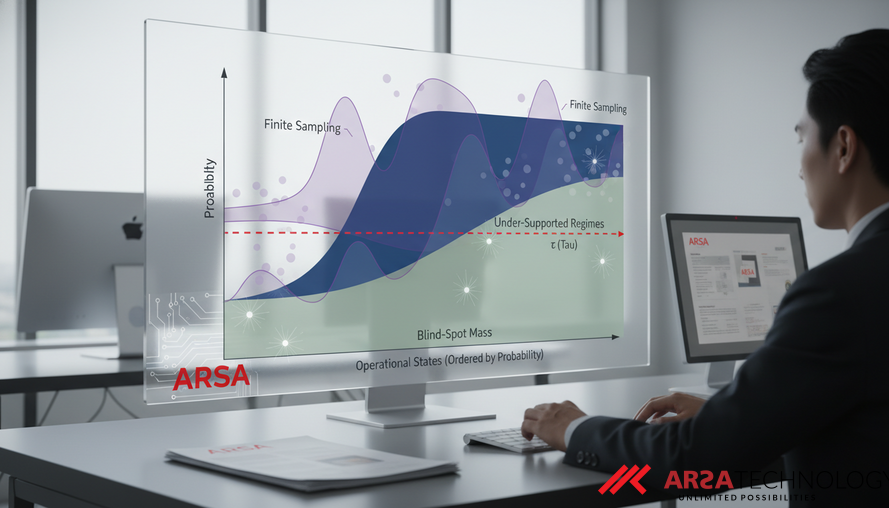
Untuk mengatasi "kebutaan cakupan" ini, diperlukan sebuah metrik yang dapat mengukur seberapa besar bagian dari distribusi operasional yang berada dalam kondisi kritis dan kurang didukung data. Artikel ini akan membahas konsep Blind-Spot Mass, sebuah kerangka kerja yang menggunakan prinsip Good-Turing untuk mengukur risiko cakupan implementasi dalam sistem ML. Konsep ini pertama kali diusulkan dalam makalah "Blind-Spot Mass: A Good-Turing Framework for Quantifying Deployment Coverage Risk in Machine Learning Systems" oleh Pal, Bhattacharya, dan Singh (2026), yang dapat ditemukan pada tautan ini.
Memahami Blind-Spot Mass: Kerangka Kerja Good-Turing untuk Risiko Cakupan
Blind-Spot Mass ($B_n(τ)$) adalah metrik implementasi yang dirancang untuk memperkirakan total massa probabilitas yang dialokasikan pada kondisi-kondisi yang dukungan empirisnya (frekuensi kemunculan dalam data pelatihan) berada di bawah ambang batas $τ$. Ambang batas $τ$ ini merepresentasikan tingkat dukungan data minimum yang dianggap perlu untuk memastikan keandalan model. Jika sebuah kondisi muncul kurang dari $τ$ kali dalam data pelatihan, model dianggap memiliki "titik buta" untuk kondisi tersebut.
Konsep ini dihitung menggunakan estimasi "unseen species" dari Good-Turing, sebuah teori statistik yang awalnya dikembangkan untuk memperkirakan probabilitas menemukan kategori yang belum pernah terlihat dari sampel yang terbatas. Dalam konteks ML, data pelatihan dan kalibrasi adalah sampel terbatas dari distribusi operasional. Teori Good-Turing memungkinkan estimasi berapa banyak dari distribusi operasional yang terletak pada rezim yang kurang didukung dan kritis terhadap keandalan. Dengan demikian, Blind-Spot Mass memberikan estimasi yang terukur tentang seberapa besar "bagian yang tidak terlihat" dari dunia operasional bagi model.
Mengapa ini penting? Tanpa kerangka kerja seperti Blind-Spot Mass, organisasi mungkin menginvestasikan sumber daya besar untuk meningkatkan akurasi model pada data yang sudah dikenal, sementara masalah keandalan sebenarnya terletak pada "ekor panjang" distribusi operasional. Dengan mengidentifikasi massa probabilitas yang kurang didukung ini, perusahaan dapat mengambil keputusan yang lebih tepat mengenai pengumpulan data tambahan, strategi mitigasi risiko, dan desain arsitektur sistem.
Membedah Kinerja: Batas Akurasi yang Dikenakan Cakupan
Selain mengukur Blind-Spot Mass, kerangka kerja ini juga memperkenalkan "batas akurasi yang dikenakan cakupan" (coverage-imposed accuracy ceiling). Batas ini memecah kinerja keseluruhan model menjadi dua komponen utama: kinerja di wilayah yang "didukung" (di mana ada cukup data pelatihan) dan kinerja di wilayah "buta" (di mana data pelatihan kurang). Pembongkaran ini sangat penting karena memungkinkan praktisi untuk membedakan antara batasan yang disebabkan oleh kapasitas model (misalnya, model tidak cukup kompleks untuk mempelajari pola yang ada) dan batasan yang disebabkan oleh keterbatasan data (tidak ada cukup contoh untuk mempelajari pola tertentu).
Sebagai contoh, jika sebuah model memiliki akurasi yang rendah di wilayah "buta" meskipun memiliki kapasitas yang tinggi, ini menunjukkan bahwa masalahnya bukan pada kemampuan belajar model, melainkan pada kurangnya data yang memadai di wilayah tersebut. Sebaliknya, jika model berkinerja buruk di wilayah yang "didukung", ini mungkin menunjukkan bahwa kapasitas model perlu ditingkatkan atau arsitektur model perlu dioptimalkan. Analisis ini memberikan panduan yang jelas untuk strategi peningkatan model, apakah itu memerlukan lebih banyak data, data yang lebih beragam, atau arsitektur model yang berbeda.
Dalam implementasi sistem AI seperti analitik video AI untuk pemantauan keselamatan atau pengawasan, pemahaman ini sangat krusial. Sistem harus dapat beroperasi secara andal tidak hanya dalam skenario umum tetapi juga dalam situasi yang jarang terjadi namun berpotensi kritis, seperti kondisi pencahayaan yang tidak biasa atau perilaku yang tidak terduga.
Validasi Empiris: Dari Aktivitas Manusia hingga Data Klinis
Kerangka kerja Blind-Spot Mass telah divalidasi secara empiris di dua domain yang sangat berbeda, membuktikan generalisasinya. Pertama, dalam domain wearable human activity recognition (HAR) menggunakan data inersia dari pergelangan tangan. Domain ini secara inheren menghadapi variasi kombinatorial yang tinggi—misalnya, ukuran tubuh, gaya berjalan, posisi perangkat yang bergeser, pakaian, dan lingkungan. Model AI di edge dalam konteks ini harus tetap ringkas namun andal. Hasilnya menunjukkan bahwa di bawah abstraksi operasional yang disempurnakan, sekitar 95% dari massa probabilitas implementasi berada di bawah $τ=5$. Ini menyiratkan bahwa sebagian besar rezim aktivitas manusia yang valid secara efektif "tidak terlihat" oleh dukungan data pelatihan yang ada.
Validasi kedua dilakukan dalam basis data rumah sakit MIMIC-IV (275 kasus penerimaan pasien), di mana kurva Blind-Spot Mass menunjukkan konvergensi yang sama sekitar 95% pada $τ=5$ di seluruh abstraksi kondisi klinis. Replikasi ini melintasi domain-domain yang secara struktural independen — yang berbeda dalam modalitas, ruang fitur, ruang label, dan aplikasi — menunjukkan bahwa Blind-Spot Mass adalah metodologi ML umum untuk mengukur risiko cakupan kombinatorial, bukan hanya artefak spesifik aplikasi.
Temuan ini sangat relevan untuk perusahaan seperti ARSA Technology yang mengembangkan sistem ARSA AI Box Series untuk penerapan AI di edge, di mana model harus beroperasi dalam batasan sumber daya dan lingkungan yang bervariasi. Memahami Blind-Spot Mass memungkinkan pengembangan model yang lebih tangguh dan akurat bahkan untuk kasus-kasus yang jarang terjadi.
Blind-Spot Decomposition: Wawasan untuk Praktisi Industri
Salah satu manfaat paling signifikan dari Blind-Spot Mass adalah kemampuannya untuk melakukan dekomposisi titik buta (blind-spot decomposition). Ini berarti kerangka kerja tersebut dapat mengidentifikasi aktivitas atau rezim klinis mana yang paling dominan dalam menyumbang risiko cakupan. Wawasan ini sangat berharga bagi praktisi industri karena memberikan panduan yang dapat ditindaklanjuti untuk:
- Pengumpulan Data yang Ditargetkan: Daripada mengumpulkan data secara acak, perusahaan dapat mengidentifikasi secara spesifik jenis data atau kondisi yang paling kurang terwakili dan memprioritaskan pengumpulannya. Ini mengurangi biaya dan waktu pengembangan.
- Normalisasi/Renormalisasi: Memungkinkan penyesuaian strategi normalisasi data untuk memastikan bahwa kondisi yang langka tidak terlalu diredam atau dihilangkan, sehingga model dapat mempelajarinya dengan lebih baik.
- Batasan yang Diinformasikan Fisika atau Domain: Menerapkan batasan atau asumsi yang berasal dari pemahaman mendalam tentang fisika atau domain aplikasi untuk mengurangi kerumitan ruang kondisi, sehingga model tidak perlu mempelajari setiap variasi yang tidak relevan.
Misalnya, dalam penerapan AI BOX - Basic Safety Guard untuk pemantauan keselamatan di lingkungan industri, dekomposisi Blind-Spot Mass dapat membantu mengidentifikasi skenario keselamatan tertentu (misalnya, jenis insiden yang jarang terjadi, penggunaan APD yang tidak standar dalam kondisi tertentu) yang memerlukan lebih banyak data atau aturan yang lebih eksplisit untuk memastikan keandalan deteksi.
Perbandingan dengan Metode Penilaian Risiko Lainnya
Penting untuk memahami bahwa Blind-Spot Mass bukan pengganti, melainkan pelengkap, alat penilaian risiko lainnya:
Deteksi Out-of-Distribution (OOD): Metode OOD mengidentifikasi input individual yang tidak mungkin di bawah distribusi pelatihan pada waktu inferensi. Sebaliknya, Blind-Spot Mass mengukur agregat massa probabilitas di wilayah yang kurang didukung sebelum implementasi*. Sebuah sistem bisa memiliki tingkat OOD yang rendah namun tetap menderita dukungan yang sangat kurang di "ekor panjang" di dalam manifold distribusi. Prediksi Konformal (Conformal Prediction): Prediksi konformal memberikan jaminan cakupan marginal dengan sampel terbatas di bawah asumsi kalibrasi. Blind-Spot Mass* adalah diagnostik hulu yang menginformasikan apakah data yang tersedia cukup untuk memenuhi persyaratan keandalan tertentu sebelum jaminan konformal menjadi bermakna secara operasional. Deteksi dan Pemantauan Pergeseran (Shift Detection): Metode ini bertujuan untuk menentukan apakah data implementasi menyimpang dari data pelatihan. Blind-Spot Mass* berfokus pada kuantifikasi risiko cakupan awal yang melekat pada struktur pengambilan sampel data pelatihan dari distribusi operasional.
Singkatnya, Blind-Spot Mass menjawab pertanyaan fundamental yang tidak dapat dijawab oleh metode lain: "Berapa banyak dari distribusi implementasi yang berada di wilayah di mana model memiliki dukungan data yang tidak memadai untuk menjadi andal?"
Kesimpulan: Membangun Sistem AI yang Lebih Andal
Kerangka kerja Blind-Spot Mass menawarkan pendekatan yang inovatif dan terukur untuk mengatasi salah satu tantangan terbesar dalam implementasi sistem ML: keandalan di hadapan kondisi operasional yang kompleks dan bervariasi. Dengan mengidentifikasi dan mengukur massa probabilitas di "titik buta" data, organisasi dapat membuat keputusan yang lebih cerdas dan strategis untuk pengumpulan data, desain model, dan strategi implementasi.
Pendekatan ini tidak hanya meningkatkan akurasi, tetapi juga memperkuat kepercayaan dan utilitas sistem AI di dunia nyata. Dengan menerapkan wawasan dari Blind-Spot Mass, perusahaan dapat membangun sistem AI yang tidak hanya cerdas tetapi juga tangguh dan benar-benar andal.
Jika Anda tertarik untuk menjelajahi bagaimana ARSA Technology dapat membantu Anda membangun dan menerapkan solusi AI yang andal dan siap produksi untuk kebutuhan unik industri Anda, jangan ragu untuk menghubungi tim ARSA untuk konsultasi gratis.
Sumber: Pal, B., Bhattacharya, S., & Singh, M. (2026). Blind-Spot Mass: A Good–Turing Framework for Quantifying Deployment Coverage Risk in Machine Learning Systems. Journal of Machine Learning Research, 0, 1-15. https://arxiv.org/abs/2604.05057.